
Accurately Labeling Subjective Question-Answer Content Using BERT
A NLP Tutorial on a 6th Place Solution for Kaggle Q&A Understanding Competition
Introduction
Kaggle released Q&A understanding competition at the beginning of 2020. This competition asks each team to build NLP models to predict the subjective ratings of question and answer pairs. We finished it with 6th place in all 1571 teams. Apart from a winning solution blog posted in Kaggle, we write this more beginner friendly tutorial to introduce the competition and how we won the gold medal. We also open source our code in this Github repository.
Data
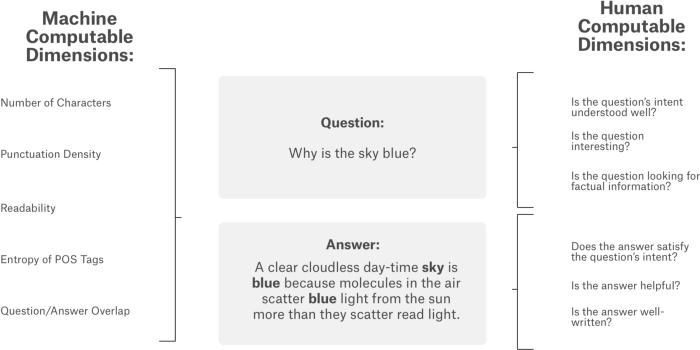
The competition collects question and answer pairs from 70 Stack-Overflow-like websites, Question title, body and answer as text features, also some other features such as url, user id. The target labels are 30 dimensions with values between 0 and 1 to evaluate questions and answer such as if the question is critical, if the answer is helpful, etc. The raters received minimal guidance and training, and the target relied largely on their subjective interpretation. In other words, the target score is simply from raters common-sense. The target variables were the result of averaging the classification of multiple raters. i.e. if there are four raters, one classifies it a positive and the other three as a negative, the target value will be 0.25. Here is an example of the question
- Question title: What am I losing when using extension tubes instead of a macro lens?
- Question body: After playing around with macro photography on-the-cheap (read: reversed lens, rev. lens mounted on a straight lens, passive extension tubes), I would like to get further with this. The problems with …
- Answer: I just got extension tubes, so here’s the skinny. …what am I losing when using tubes…? A very considerable amount of light! Increasing that distance from the end of the lens to the sensor …
The training and test set are distributed as below
| Type | With label | # samples | Purpose |
|---|---|---|---|
| Training set | Y | 6079 | Training and local test |
| Public test set | N | 476 | Public leaderboard |
| Private test set | N | 3185 | Private leaderboard |
Evaluation metrics
Spearman’s rank correlation coefficient is used as the evaluation metrics in this competition.
Intuitively, Pearson correlation is a measure of linear correlation of X and Y. For Spearman’s rank correlation, instead of using the value of X and Y, we use the ranking of X and Y in the formula. It is a measure of the monotonic relationship between X and Y. As the figure shown, the data given in the chart, pearson is 0.88 and spearman is 1.
Why was spearman used in this kaggle competition? Considering the subjective and noisy nature of the labels, Spearman correlation tends to be more robust to outliers as for instance pearson correlation. Also, because the target value is an understanding of question and answer based on rater’s common sense. Suppose we have 3 answers and we evaluate if the answers are well-written. answer A has score 0.5, answer B has score 0.2 and answer C is 0.1, If we claim answer A is 0.3 better than answer B, does it make sense? Not really. Here, we do not need the accurate value difference. It is just enough to know A is better than B and B is better than C.
NLP Pipeline

A general NLP pipeline is shown as the figure above. And a typical non-neural network-based solution could be:
- Use TF-IDF or word-embedding to get the token based vector representations
- Average the token vectors to a get document vector representation
- Use random forest or lightGBM as the classifier or the regressor
Due to the emergence of transformer and BERT in 2017 and 2018, NLP has been experiencing an “ImageNet” moment. BERT has become the dominant algorithm for NLP competitions. In this blog, we do not introduce BERT. There are several good tutorials such as here, here and here.
Now, we can restructure the NLP pipeline by using BERT:
- Use BERT wordpiece tokenizer to generate (sub)word tokens
- Generate embedding vectors per token from BERT
- Average the token vectors by a neural network pooling layer
- Use feed forward layers as the classifier or regressor
Gold Medal Solution
The big picture
As illustrated in the figure below, we use four BERT-based models and a Universal Sentence Encoder model as base models, then stack them to generate the final result. In the rest of this blog, we will only focus on the transformer/BERT models. For more information of Universal Sentence Encoder, you can visit the original paper here, and the code is available here.
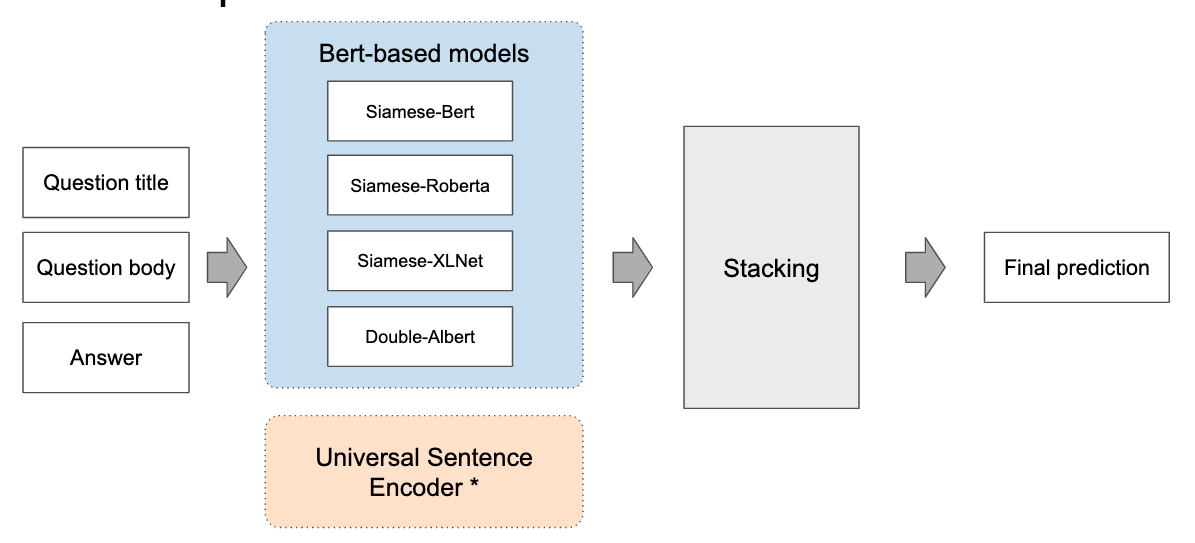
Architecture of BERT-based models
The animation below shows how one base model works. The codes are here.
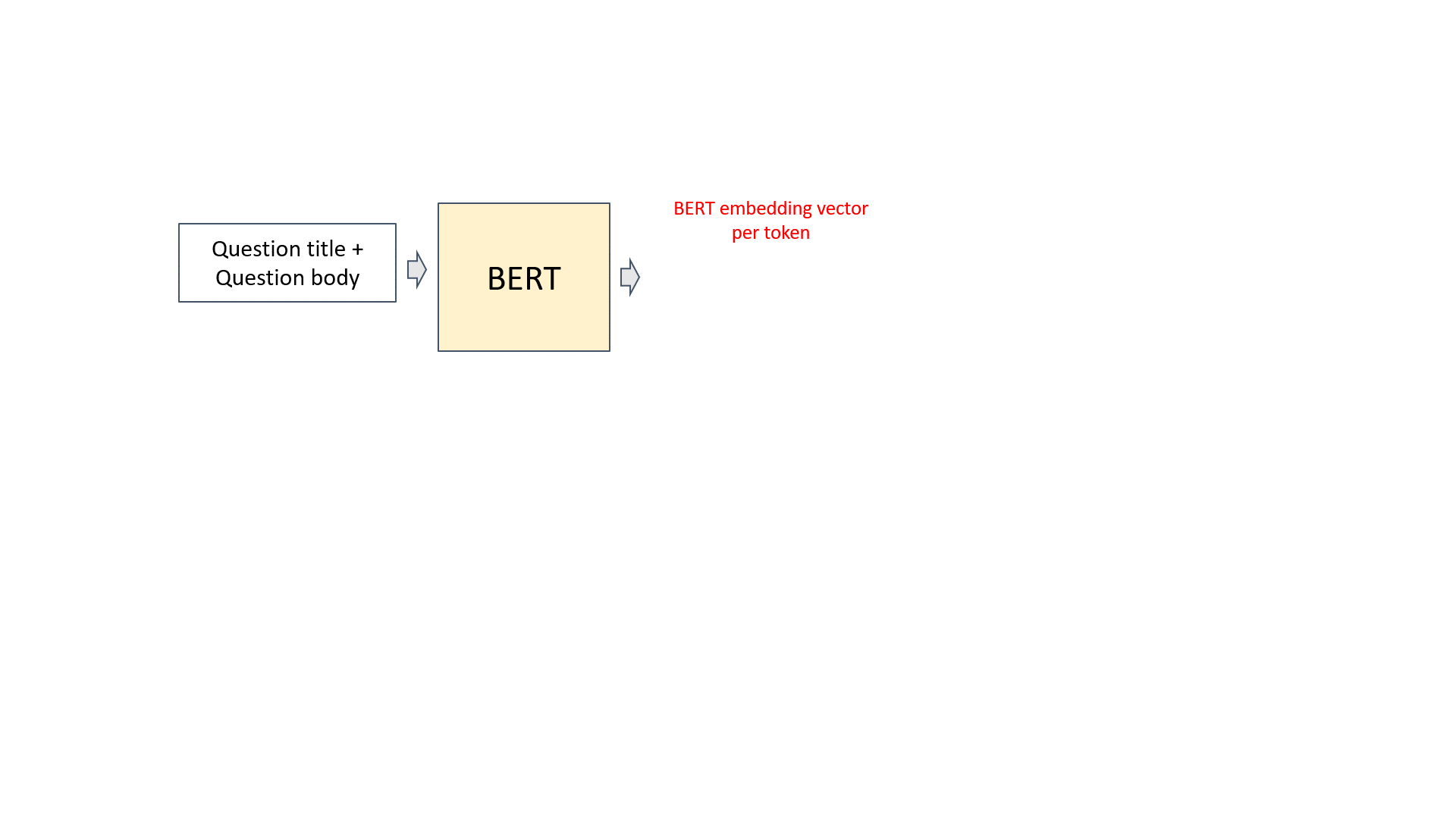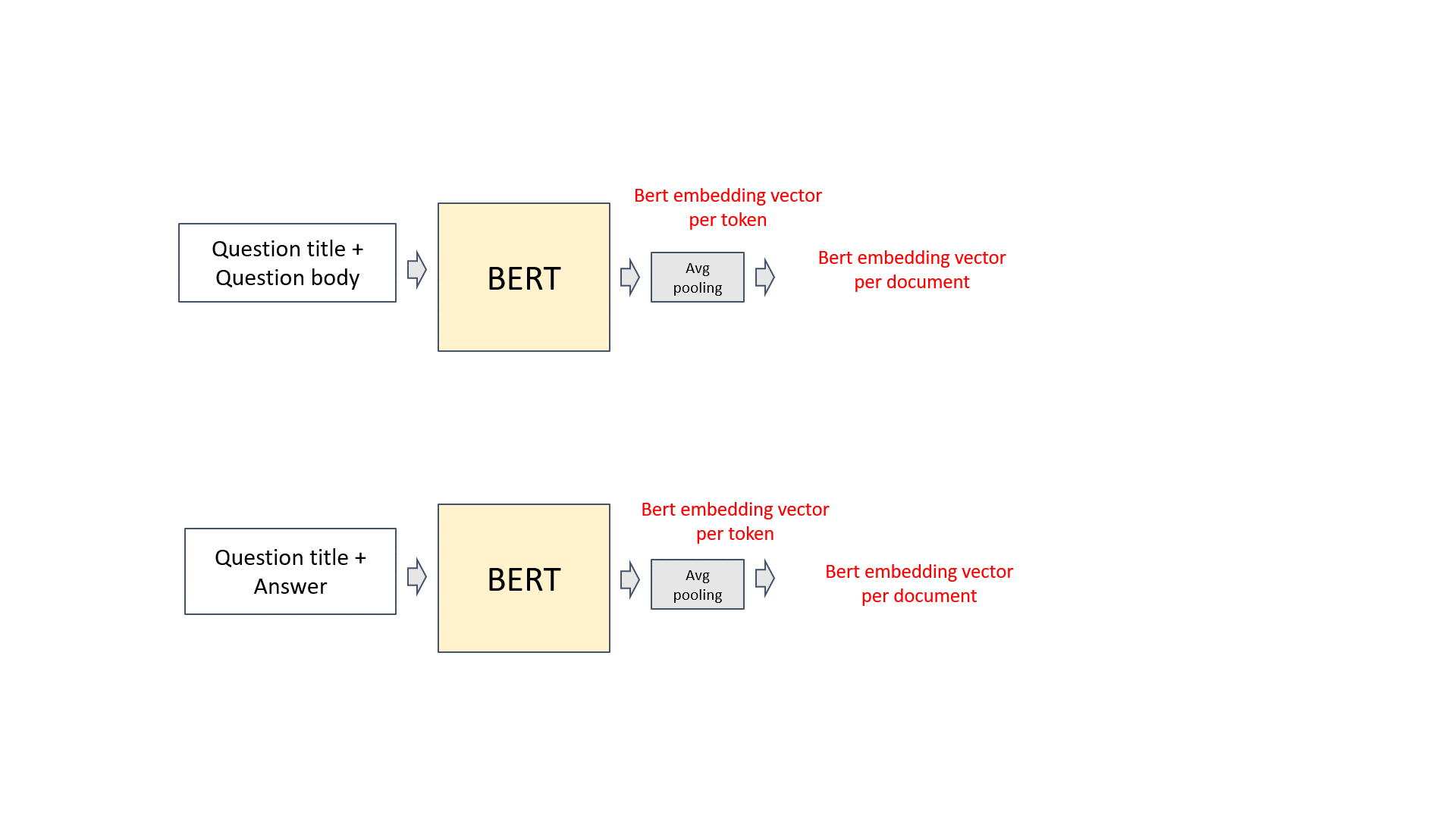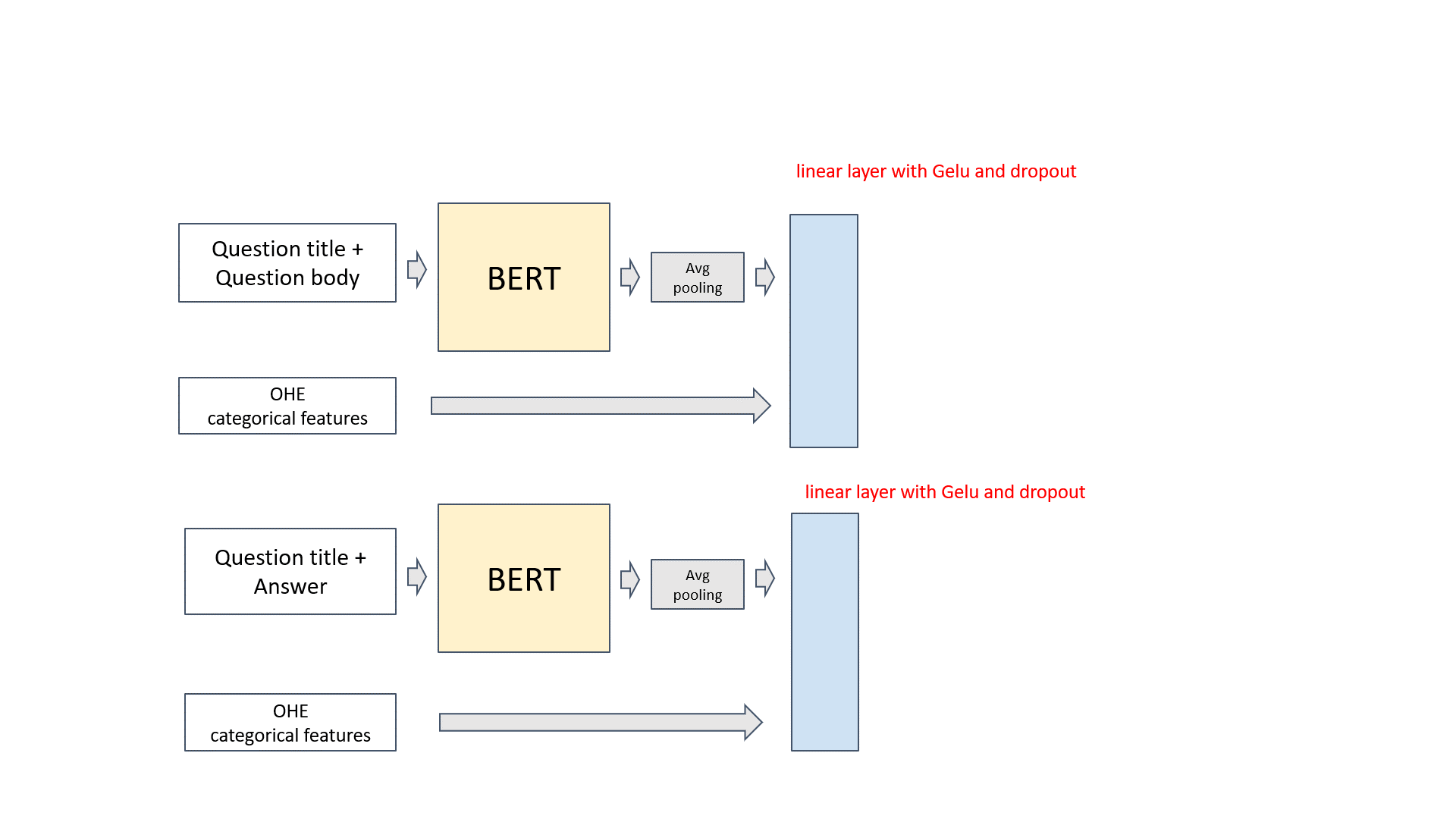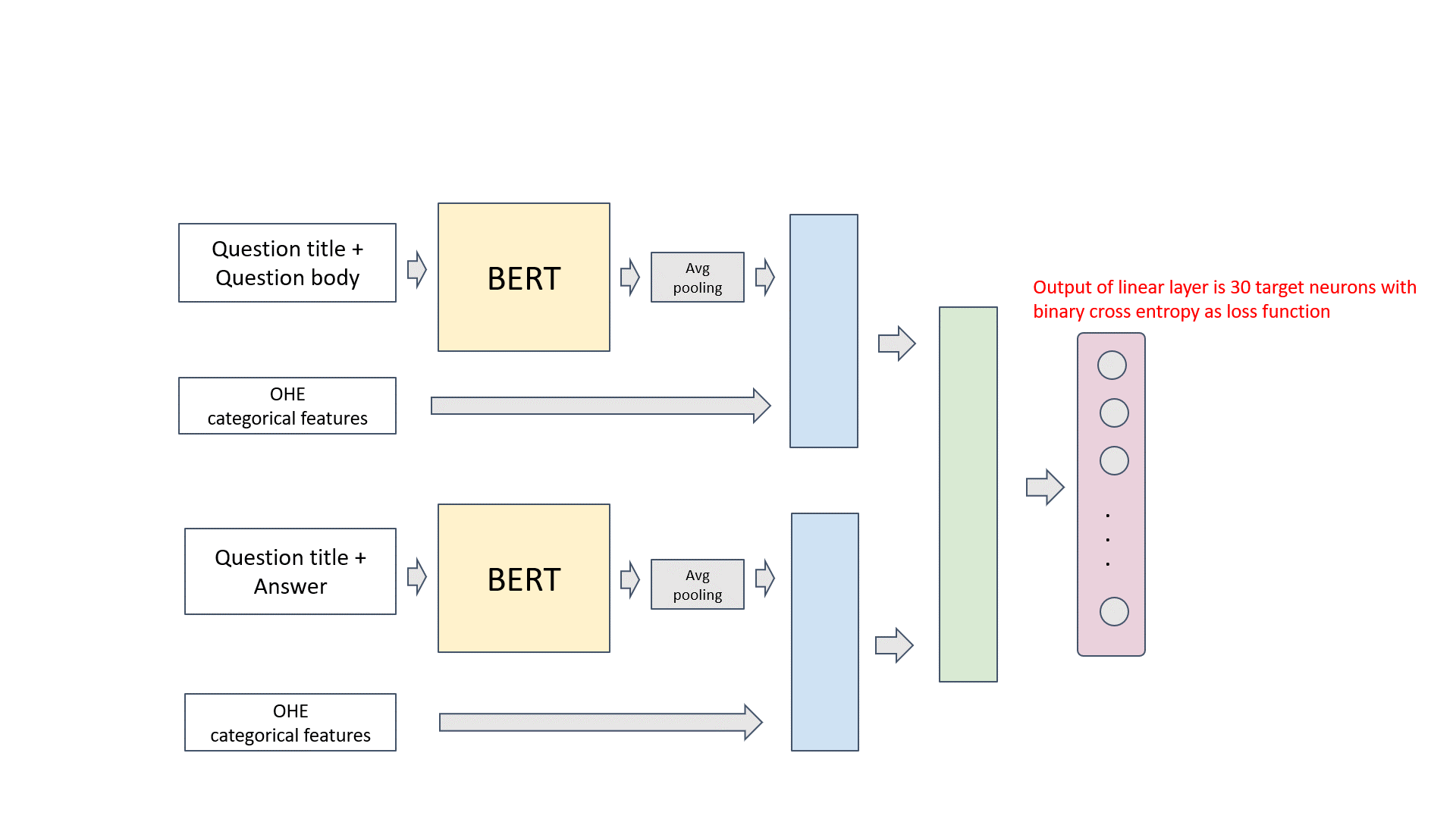
- Question title and question body are concatenated as input. BERT tokenizer is used to get sub-words, then BERT embeddings are generated. Followed by an average pooling layer, we get a vector representation for each question title and body pair. It is noted that we averaged over the token embeddings of non-masked tokens. It was something we did different from the common approaches and made a slight improvement in cross-validation. Other categorical or numerical features are appended, then connected with a linear layer with Gelu activation and dropout.
- Similarly, we have a mirror structure with question titles and answer pairs as input. We have two options. If the mirror BERT model can share the weights of the first BERT model, we call it “siamese” structure. It can also use separate weights, then we call it “double” structure. The siamese structure normally has less parameters and better generalization. We experimented with both siamese and double structure and choose the best N base models according to cross-validate scores.
- The output of both aforementioned structures are concatenated, and connected to a forward layer to get the prediction of 30 dimensional target value.
Huggingface packages most state-of-the-art NLP models Pytorch implementations. In our solution, 4 BERT based models implemented by Huggingface are selected. They are Siamese Roberta base, Siamese XLNet base, Double Albert base V2, Siamese BERT base uncased.
Training and experiment setup
We have two stage training. Stage 1 is an end-to-end parameter tuning, and stage 2 only tunes the “head”. in the first stage:
- Train for 4 epochs with huggingface AdamW optimiser. The code is here
- Binary cross-entropy loss.
- One-cycle LR schedule. Uses cosine warmup, followed by cosine decay, whilst having a mirrored schedule for momentum (i.e. cosine decay followed by cosine warmup). The code is here
- Max LR of 1e-3 for the regression head, max LR of 1e-5 for transformer backbones.
- Accumulated batch size of 8
In the second stage:
- Freeze transformer backbone and fine-tune the regression head for an additional 5 epochs with constant LR of 1e-5. The code is here
- Added about 0.002 to CV for most models.
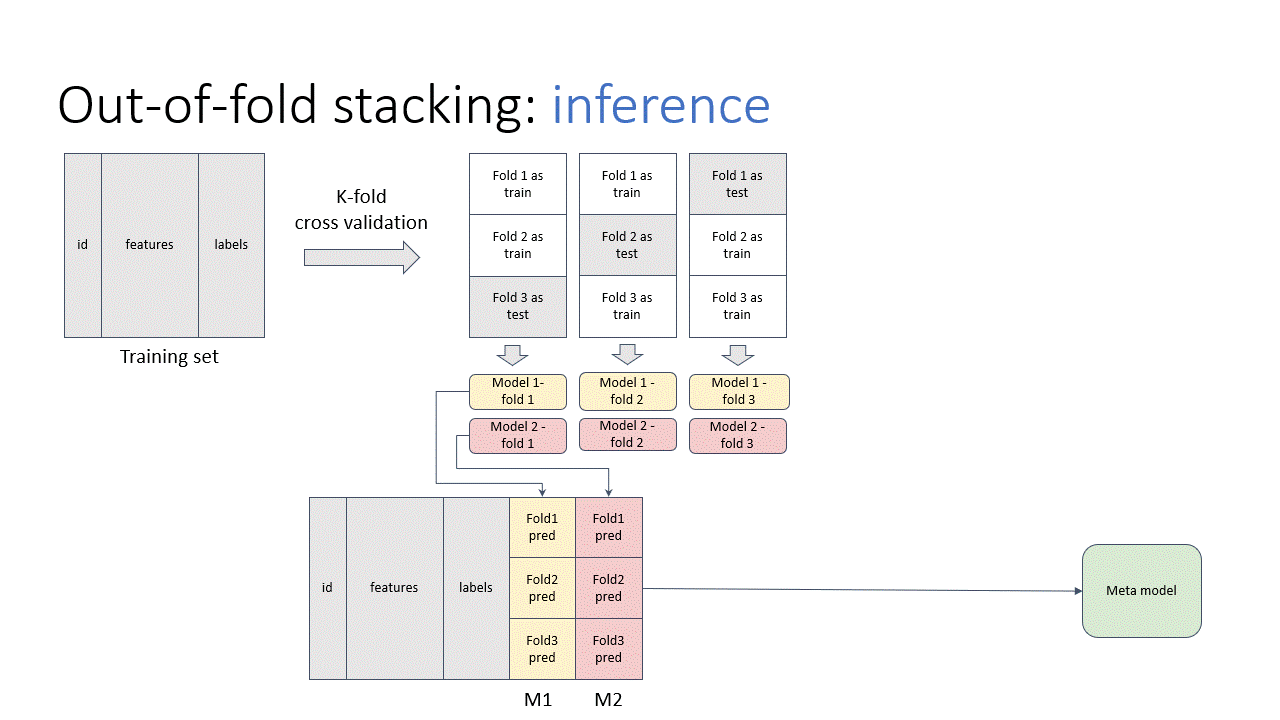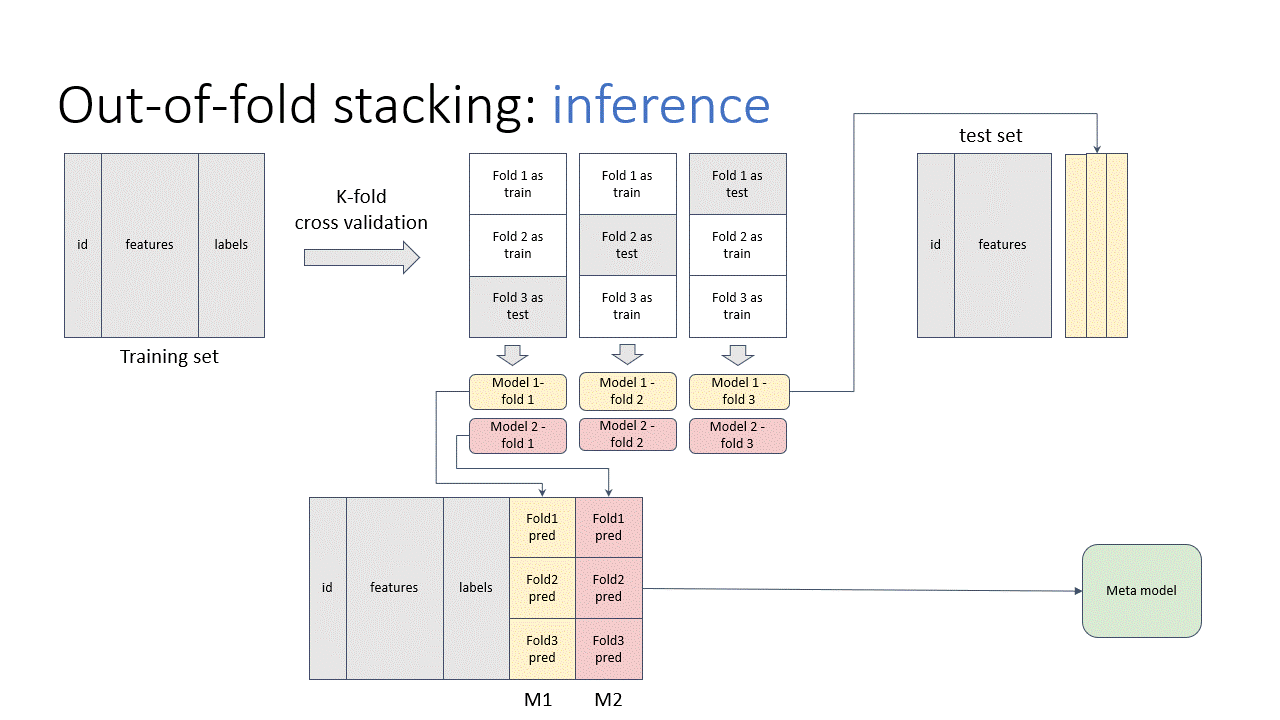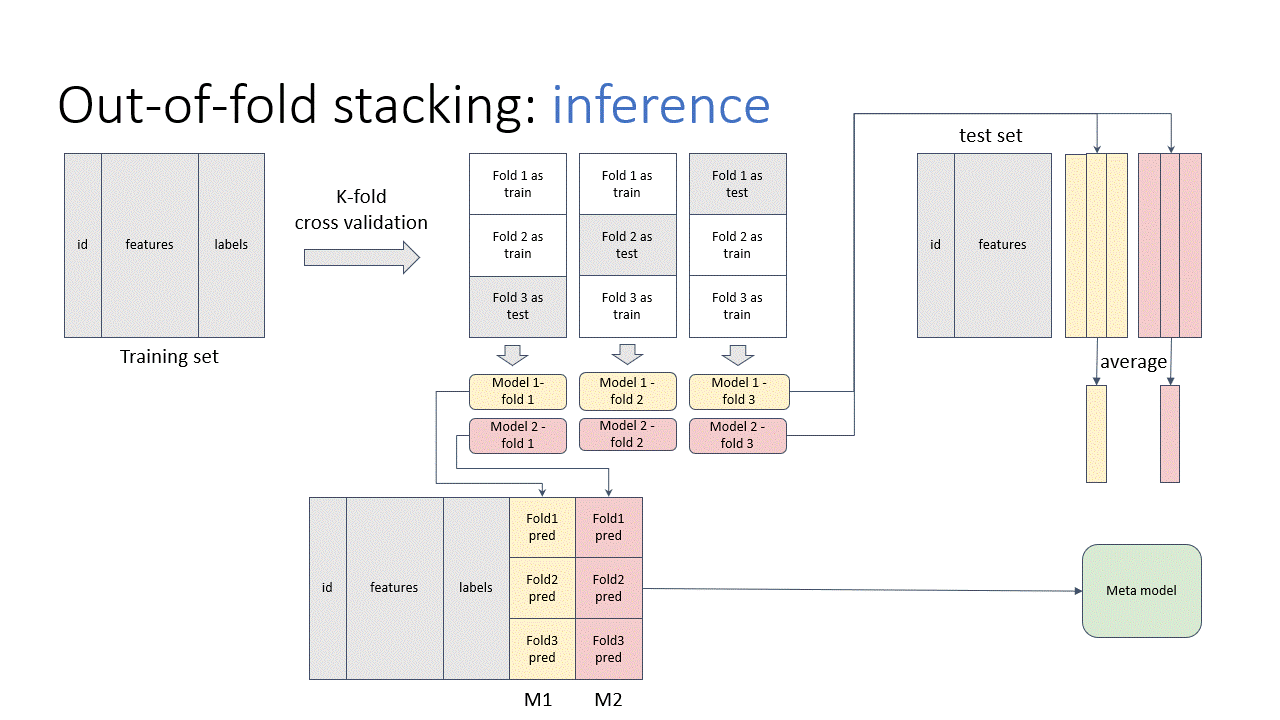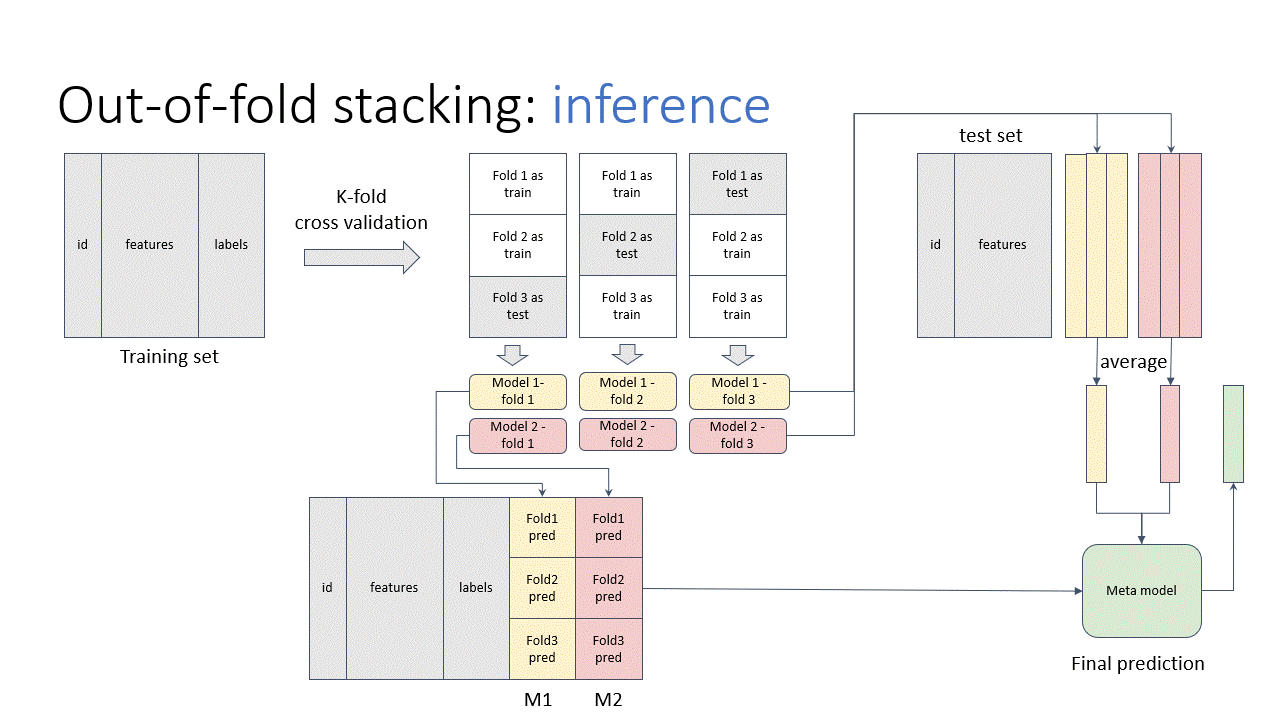
Stacking
Stacking is the “de-facto” ensemble strategy for kagglers. The animations below illustrate the training and prediction procedure. there are 3 folds in the example. To get the meta training data for each fold, we train iteratively on 2 folds and predict on the remaining fold. And the whole out-of-fold prediction is used as features. Then, we train the stacking model.
In the prediction stage, we input the test data to all out-of-fold base models to get the predictions. Then, we average the results, pass to the stacking model to get the final prediction

Other tricks
GroupKFold
Let us first have a look why normal KFold split does not work well in this competition. In the dataset, some samples were collected from one question-answer thread, which means multiple samples share the same question title and body but with different answers.
If we use a normal KFold split function, answers to the same questions will be distributed in both training set and test set. This will bring an information leakage problem. A better split is to put all question/answer pairs from the same question together in either the training set or the test set.
Fortunately, sk-learn has provided a function GroupKFold to generate non-overlapping groups for cross validation. Question body field is used to indicate the group, as the code below.
folds = GroupKFold(n_splits=n_folds).split(
X=train['question_body'],
groups=train['question_body']
)
Post-processing
As many other teams did, one post-processing step had a massive impact on the performance. The general idea is based on rounding predictions downwards to a multiple of some fraction 1/d.
def scale(x, d):
if d:
return (x//(1/d))/d
return x
So if d=4 and x = [0.12, 0.3, 0.31, 0.24, 0.7] these values will get rounded to [0.0, 0.25, 0.25, 0.0, 0.5]. For each target column we did a grid search for values of d in [4, 8, 16, 32, 64, None].
In our ensemble we exploited this technique even further, applying the rounding first to individual model predictions and again after taking a linear combination of model predictions. In doing so we did find that using a separate rounding parameter for each model, out-of-fold score improvements would no longer translate to leaderboard. We addressed this by reducing the number of rounding parameters using the same d_local across all models:
y_temp = 0
for pred, w in zip(model_preds, ws):
y_temp += w * scale(pred, d_local) / sum(ws)
y_temp = scale(y_temp, d_global)
All ensembling parameters — 2 rounding parameters and model weights — were set using a small grid search optimising the spearman rank correlation coefficient metric on out-of-fold while ignoring question targets for rows with duplicate questions. In the end, this post-processing improved our 10 fold GroupKFold CV by ~0.05.